1.1. Классификация изображений
Классификация изображений — это процесс отнесения входного изображения к одной из заранее определённых категорий (классов). На практике это может выглядеть по‑разному: от распознавания рукописных цифр до определения породы собаки на фотографии. Ниже кратко описаны основные аспекты и этапы общего процесса классификации изображений:
1. Сбор и подготовка данных
1. Сбор датасета: Качество и разнообразие данных критически важны. Для надёжного распознавания системы необходимо “видеть” различные примеры, соответствующие каждому классу (в разных ракурсах, с разным фоном и т.п.).
2. Аугментация данных: Когда данных недостаточно, их искусственно расширяют при помощи таких методов, как повороты, сдвиги, отражения, изменение масштаба и т.д. Это помогает модели научиться быть более устойчивой к вариациям во входном изображении.
3. Разделение на выборки: Данные обычно делят на обучающую (training), валидационную (validation) и тестовую (test) выборки. Обучающая выборка нужна для собственно “учёбы” модели, валидационная — для подбора гиперпараметров и контроля переобучения, а тестовая — для итоговой независимой оценки качества.
2. Традиционные методы и подходы
1. Классическое компьютерное зрение: До эпохи глубинного обучения популярны были методы, основанные на вычислении заранее заданных признаков (feature extraction). Примеры таких признаков: SIFT, HOG, SURF, LBP. Затем для классификации использовались классические алгоритмы машинного обучения (например, SVM или Random Forest).
2. Обработка цветовых каналов, текстур, контуров: Для разных задач подбирали специфические признаки (к примеру, цветовой гистограммы хватало при поиске объектов с ярко выраженным цветом).
3. Глубинные нейронные сети
В последние годы наибольшую популярность получила классификация изображений с помощью свёрточных нейронных сетей (Convolutional Neural Networks, CNN). Эти сети автоматически выделяют наиболее релевантные признаки из изображений, что снижает необходимость ручной обработки и подбора признаков.
1. Структура CNN:
Вход: Изображение (обычно преобразуется к определённому разрешению).
Свёрточные слои: Извлекают особенности (фичи) разного уровня, начиная от простых (контуры, углы) до более сложных (формы, текстуры объектов).
Пулинг (Pooling): Сжимает пространственные размеры, сохраняя важную информацию и повышая устойчивость к сдвигам.
Полносвязные слои: После серии свёрточных и пулинг-слоёв формируется вектор признаков, который используется для итоговой классификации (например, через softmax).
2. Обучение:
Функция потерь (loss function) обычно выбирается на основе задачи (например, кросс-энтропия).
Оптимизация: Параметры сети (веса) обновляются методом обратного распространения ошибки (backpropagation) с использованием алгоритмов оптимизации (SGD, Adam и др.).
Гиперпараметры: Количество слоёв, размер фильтров, скорость обучения — всё это может существенно влиять на конечную точность.
3. Преимущества глубинных методов:
Устойчивость к вариациям: CNN менее чувствительны к небольшим сдвигам или искажениям изображения.
Автоматическое выделение признаков: Отпадает необходимость ручного подбора признаков.
Масштабируемость: При наличии достаточных вычислительных ресурсов и данных можно строить очень глубокие и точные модели.
4. Метрики оценки качества
Чтобы понять, насколько хорошо модель научилась классифицировать изображения, используют различные метрики. Некоторые из самых распространённых:
1. Accuracy (точность классификации): число правильно классифицированных образцов/общее число образцов.
2. Precision, Recall, F1-score: Метрики, которые особенно важны в случае несбалансированных классов.
3. ROC-кривая и AUC: Часто используются для задач бинарной классификации.
5. Тенденции и перспективы
● Transfer Learning (переобучение готовых моделей): Большинство современных подходов в прикладных проектах начинают с уже обученных сетей, например, VGG, ResNet или EfficientNet, и затем дообучают их на целевых данных. Это сокращает время разработки и повышает точность.
● Упрощение и оптимизация сетей: В условиях ограниченных ресурсов (встраиваемые устройства, мобильные приложения) популярны модели с меньшим числом параметров (MobileNet, SqueezeNet), а также методы квантования (quantization), прунинга (pruning) и другие алгоритмы оптимизации.
● Мультиклассовая и многозадачная классификация: Модели становятся всё более универсальными — одна архитектура может одновременно решать несколько задач (детекция, классификация, сегментация и пр.).
1.2. Подробное рассмотрение формы хранения изображений и механизма свёртки
Форма хранения изображений
В компьютерном зрении цифровое изображение обычно представляется в виде многомерного массива (тензора). На практике в фреймворках глубокого обучения (Keras, PyTorch, TensorFlow) чаще всего используются два формата:
1. Channels Last (каналы последним измерением):
(B,H,W,C)
где:
B — размер батча (batch size), количество изображений, подаваемых в сеть за одну итерацию,
H — высота изображения (height),
W — ширина изображения (width),
C — количество каналов (channels), обычно 3 для цветного (RGB) или 1 для чёрно-белого (grayscale).
2. Channels First (каналы первым измерением):
(B,C,H,W)
Такой порядок часто встречается в PyTorch и некоторых других фреймворках.
Для цветных изображений, как правило, используют три канала: Red, Green, Blue. В некоторых специализированных задачах количество каналов может быть другим (например, при работе с гиперспектральными изображениями).
В Keras по умолчанию используется формат Channels Last (то есть (B,H,W,C)), поэтому при загрузке данных нужно следить, чтобы форма изображений соответствовала ожидаемой конфигурации сети.
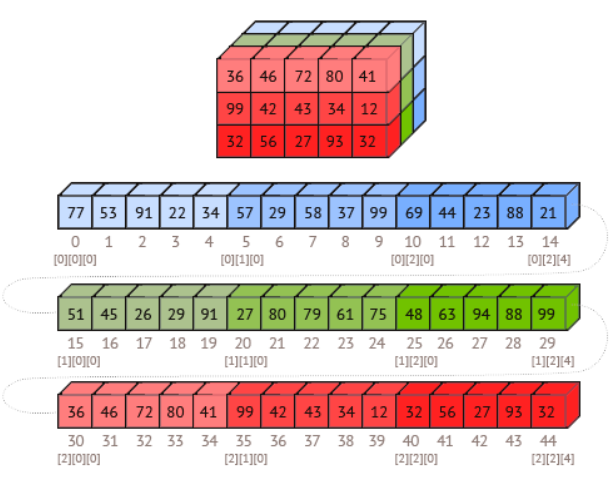
Изображение в трёхмерном массиве
Механизм свёрточных слоёв (Conv2D)
Свёрточные нейронные сети (CNN) стали основным инструментом для классификации изображений благодаря механизму «свёртки» (convolution), который позволяет эффективно выделять пространственные признаки (features) на изображении.
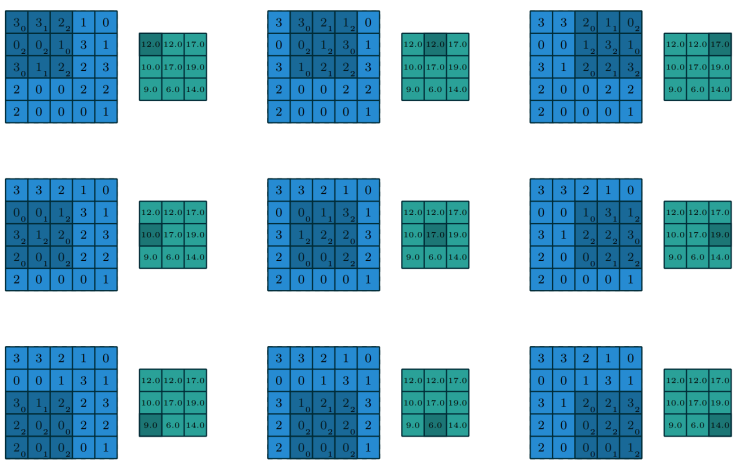
Механизм свёрточных слоёв (Conv2D)
Свёрточные нейронные сети (CNN) стали основным инструментом для классификации изображений благодаря механизму «свёртки» (convolution), который позволяет эффективно выделять пространственные признаки (features) на изображении.
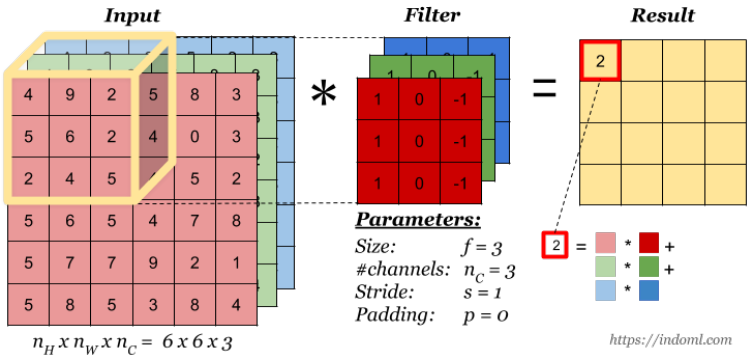
Ещё один пример свёртки на многоканальных данных
1. Ядро (фильтр) свёртки
Представляет собой небольшой по размеру двумерный массив весов (например, 3×33×3 или 5×55×5).
Если вход имеет несколько каналов, ядро “растягивается” по всем каналам. То есть для входа с C каналами само ядро будет иметь размер (kh×kw×C).
2. Применение фильтра
Фильтр последовательно «скользит» по входному изображению, умножая пиксели на соответствующие элементы ядра и суммируя их.
В результате на выходе каждого такого умножения формируется “карта признаков” (feature map).
Поскольку фильтров обычно несколько, формируется столько карт признаков, сколько фильтров в слое свёртки.
3. Параметры свёртки
○ Шаг (stride): На сколько пикселей фильтр сдвигается при каждом перемещении. Больший шаг уменьшает выходные карты признаков, меньший — даёт более детальную обработку.
○ Дополнение (padding): Добавление «бордюра» (обычно нулей) вокруг исходного изображения, чтобы сохранить размер на выходе или контролировать размерность во время свёртки (Valid, Same-пэддинг и т.д.).
4. Обучение фильтров
Веса (множители) в ядрах свёртки не задаются вручную, а оптимизируются автоматически в процессе обучения.
Во время обратного распространения ошибки (backpropagation) модель получает сигнал о том, какие фильтры и как именно нужно скорректировать, чтобы улучшить итоговую классификацию.
Многослойная структура свёрточной сети
Небольшая свёрточная операция, применённая один раз, выделяет лишь самые простые признаки (например, контуры вертикальной или горизонтальной направленности). Однако сила современных свёрточных сетей в том, что они используют последовательность нескольких (а иногда и десятков) свёрточных слоёв:
1. Начальные слои
Извлекают простые паттерны (границы, линии, контуры).
2. Серединные слои
Сочетают простые признаки в более сложные, распознают текстуры, формы, части объектов.
3. Глубокие слои
«Собирают» высокоуровневые концепции (целые объекты, классы объектов, детали лица и т.д.).
4. Выходные слои
Обычно полносвязный слой (Dense) со softmax-активацией для классификации на нужное число классов.
В итоге, модель «видит» изображение как набор полезных признаков, последовательно абстрагируясь от локальных деталей к более общим формам.
Преимущество автоматического обучения весов
Главная идея глубокого обучения в том, что все параметры (веса фильтров свёртки, коэффициенты в полносвязных слоях и пр.) модель настраивает сама. Для классификации изображений это важно, потому что:
● Нет необходимости вручную “придумывать” алгоритм или устанавливать правила для каждого класса.
● Модель «учится» распознавать важные паттерны, исходя только из «входных данных» и «указанных правильных ответов» (метки классов).
● При наличии большого объёма изображений хорошая свёрточная сеть может достичь очень высокой точности, выявляя даже те закономерности, которые могут быть неочевидны человеку.
1.3. Классификация изображений с помощью Keras
В этом разделе разберём, как организовать простейший конвейер для классификации изображений с помощью библиотеки Keras (TensorFlow). Мы:
1. Подготовим данные (соберём изображения по папкам, прочитаем их в NumPy‑массивы).
2. Построим простую свёрточную нейронную сеть для классификации.
3. Обучим её на наших данных.
1. Структура папок
Допустим, у нас есть такая структура директорий:
dataset/
├── train/
│ ├── men/ # Картинки кошек для обучения
│ └── women/ # Картинки собак для обучения
└── val/
├── men/ # Картинки кошек для валидации
└── women/ # Картинки собак для валидации
● train — папка с обучающими данными (каждая подпапка — отдельный класс).
● val — папка с валидационными данными, по аналогичному принципу.
В реальной задаче папок может быть больше (классов больше), а сами изображения могут иметь разное разрешение.
2. Загрузка изображений в NumPy-массив
В следующем коде мы:
● Выбираем целевое разрешение изображений (IMG_SIZE).
● Проходимся по всем подпапкам (классам).
● Для каждого файла считываем картинку (используя OpenCV или Pillow), приводим её к нужному размеру и добавляем в общий список.
● Аналогично формируем списки меток (labels).
import os
import cv2
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers, models
def load_data_from_directory(base_dir, img_size=(64, 64)):
«»»
Считывает все изображения из подпапок base_dir.
Каждая подпапка рассматривается как отдельный класс.
Возвращает кортеж (X, y, class_names).
— X: NumPy-массив изображений
— y: NumPy-массив меток классов (int)
— class_names: список названий классов
«»»
X = []
y = []
# Список подпапок (каждая — название класса)
class_names = sorted(os.listdir(base_dir))
class_names = [cn for cn in class_names if os.path.isdir(os.path.join(base_dir, cn))]
for label, class_name in enumerate(class_names):
class_folder = os.path.join(base_dir, class_name)
# Перебираем все файлы в текущей папке класса
for file_name in os.listdir(class_folder):
file_path = os.path.join(class_folder, file_name)
# Допустим, загружаем только файлы с расширением .jpg, .png и т.п.
if not file_name.lower().endswith((‘.jpg’, ‘.jpeg’, ‘.png’)):
continue
# Считываем изображение (OpenCV читает в BGR-формате)
img = cv2.imread(file_path)
if img is None:
continue
# Изменяем размер
img = cv2.resize(img, img_size)
# Переводим BGR → RGB (необязательно, если сеть обучается на BGR)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
X.append(img)
y.append(label)
X = np.array(X, dtype=np.float32)
y = np.array(y, dtype=np.int32)
return X, y, class_names
# Пример использования:
IMG_SIZE = (64, 64)
# Пути к данным (тренировочным и валидационным)
train_dir = «dataset/train»
val_dir = «dataset/val»
# Загрузка тренировочного набора
X_train, y_train, class_names_train = load_data_from_directory(train_dir, IMG_SIZE)
# Загрузка валидационного набора
X_val, y_val, class_names_val = load_data_from_directory(val_dir, IMG_SIZE)
# Проверим, что классы одинаковые и в том же порядке
assert class_names_train == class_names_val, «Список классов в train и val должен совпадать!»
class_names = class_names_train
print(«Форма X_train:», X_train.shape)
print(«Форма y_train:», y_train.shape)
print(«Форма X_val:», X_val.shape)
print(«Форма y_val:», y_val.shape)
print(«Названия классов:», class_names)
Нормализация
Обычно перед подачей в сеть данные нормализуют к промежутку [0,1] или [−1,1]. Самый простой способ — разделить на 255.0:
X_train = X_train / 255.0
X_val = X_val / 255.0
3. Создание и обучение модели
Теперь создадим простую свёрточную сеть на Keras. Допустим, у нас два класса: «кошки» и «собаки» (или сколько угодно других классов). Для вывода используем слой Dense с softmax.
num_classes = len(class_names)
model = models.Sequential([
# Блок 1
layers.Conv2D(32, (3, 3), activation=’relu’, input_shape=(IMG_SIZE[0], IMG_SIZE[1], 3)),
layers.MaxPooling2D((2, 2)),
# Блок 2
layers.Conv2D(64, (3, 3), activation=’relu’),
layers.MaxPooling2D((2, 2)),
# Блок 3
layers.Conv2D(128, (3, 3), activation=’relu’),
layers.MaxPooling2D((2, 2)),
# Выравниваем в вектор
layers.Flatten(),
# Полносвязные слои
layers.Dense(128, activation=’relu’),
layers.Dropout(0.5),
# Выходной слой
layers.Dense(num_classes, activation=’softmax’)
])
# Компиляция модели
model.compile(optimizer=’adam’,
loss=’sparse_categorical_crossentropy’,
metrics=[‘accuracy’])
model.summary()
Обучение модели
EPOCHS = 10
BATCH_SIZE = 32
history = model.fit(
X_train,
y_train,
validation_data=(X_val, y_val),
epochs=EPOCHS,
batch_size=BATCH_SIZE
)
После этого у нас будет обученная модель. Метрики обучения (значения loss и accuracy для train и validation) мы можем посмотреть в history.history, а также по желанию построить графики.
4. Предсказание на новых изображениях
Когда модель обучена, можно делать предсказания для новых картинок:
# Пример: загрузим одну случайную картинку
test_img_path = «test_cat.jpg»
test_img = cv2.imread(test_img_path)
test_img = cv2.cvtColor(test_img, cv2.COLOR_BGR2RGB)
test_img = cv2.resize(test_img, IMG_SIZE)
test_img = test_img / 255.0
# Преобразуем в форму (1, H, W, C)
test_img = np.expand_dims(test_img, axis=0)
# Предсказание
pred = model.predict(test_img)
class_index = np.argmax(pred, axis=1)[0]
class_label = class_names[class_index]
print(f»Определён класс: {class_label}, увереность: {pred[0][class_index]*100:.2f}%»)
5. Ключевые моменты
1. Подготовка данных: Важно проверять, что каждая папка действительно содержит изображения одного класса, и что формат данных корректен.
2. Формирование батчей: В нашем примере мы загружаем всё сразу в память. Если данных очень много, стоит использовать генераторы (например, tf.keras.utils.Sequence или ImageDataGenerator).
3. Аугментация: При необходимости можно добавить аугментацию (случайные повороты, сдвиги, отражения и т.д.) для повышения обобщающей способности модели.
4. Мониторинг переобучения: Следите за разницей между точностью на обучении и валидации. При необходимости уменьшайте переобучение с помощью Dropout, регуляризации или иных методов.
Таким образом, мы создали простейший конвейер:
● Собрали изображения по классам,
● Загрузили их в NumPy,
● Нормализовали,
● Построили небольшую свёрточную сеть,
● Обучили её и сделали предсказания.
Данный подход удобен для базовых экспериментов и наглядного понимания устройства классификации в Keras. Для более продвинутых проектов могут потребоваться:
● Готовые предобученные модели (transfer learning),
● Сложные архитектуры (ResNet, EfficientNet, Inception и др.),
● Специальные инструменты для чтения данных (dataset API, tf.data, генераторы) и т.д.
Но основа всегда та же: Входные изображения → Свёрточная сеть → Предсказание класса.
1.4. Классификация изображений лиц на пол, тип внешности, расу и эмоции
Классификация лиц по различным признакам (пол, возраст, раса, эмоции и др.) — важное направление компьютерного зрения. В основе лежит задача выделения и анализа признаков человеческого лица. Ниже рассмотрим общие подходы и ключевые аспекты такого рода классификации.
1. Предварительный этап: детекция лица
Прежде чем классифицировать лицо, обычно нужно обнаружить (детектировать) его на изображении. Часто для этого используют:
● Haar Cascades (более старый классический метод),
● MTCNN (Multi-Task Cascaded Convolutional Networks),
● Dlib (HOG + SVM или CNN-детектор),
● Модели семейства YOLO, RetinaFace, FaceBoxes и др.
Если входные данные уже содержат выделенную область лица (кроп), то этап детекции можно пропустить.
2. Целевые признаки классификации
1. Пол
Самая простая бинарная классификация (мужчина/женщина).
2. Тип внешности, раса
Более сложная задача: спектр внешних признаков может быть широк (европеоидная, азиатская, афро-американская и т.д.).
3. Эмоции
Типовые классы: радость, грусть, удивление, гнев, страх, отвращение, нейтральное выражение и т.д.
Задача осложняется тем, что эмоции могут проявляться по-разному у разных людей и в разных культурных контекстах.
4. Возраст, возрастная группа
Часто встречается в реальных задачах.
В зависимости от постановки задачи может быть одна классификация (например, только пол), либо многозадачная модель, которая на одном и том же кропе лица делает сразу несколько предсказаний: пол, возраст, эмоция и т. п.
3. Сбор данных и подготовка выборки
1. Датасеты
Для эмоджи-классификации: FER2013, RAF-DB (Real-world Affective Faces Database), CK+ (Cohn-Kanade), AffectNet и т.д.
Для пола и возраста: IMDB-WIKI, UTKFace (содержит также расовую принадлежность), Adience и др.
2. Разметка
Данные должны быть корректно размечены по необходимым признакам.
Важно контролировать репрезентативность классов: не должно быть слишком мало примеров некоторого класса (гендерного, расового или эмоционального), иначе модель переучится на более массовых категориях.
3. Предобработка и аугментация
Общее выравнивание лиц (face alignment) — чтобы глаза находились примерно на одной горизонтали.
Аугментации: повороты, сдвиги, лёгкие искажения цвета, изменение яркости/контрастности. Это помогает модели научиться быть более устойчивой к реальным условиям съёмки.
4. Архитектура модели
Для классификации лиц по определённому признаку (или нескольким) можно использовать классические свёрточные сети, аналогичные тем, что применяются в общей классификации (см. предыдущие пункты). Однако есть несколько специфик:
1. Специализированные архитектуры для лица
VGGFace или Facenet — модели, которые изначально обучены на большой базе изображений лиц. Их можно дообучить (transfer learning) под нужные признаки.
2. Упрощённые CNN
Для задач типа «мужчина/женщина» или «улыбается/не улыбается» часто достаточно небольшой сети: 2–3 блока свёрток, Pooling, Flatten, Dense.
Если же нужно определять эмоции из многих классов + при большом разнообразии лиц, лучше использовать более глубокие сети (ResNet, MobileNet, EfficientNet и т.д.).
3. Многозадачный подход (multi-task learning)
Одна сеть может одновременно предсказывать пол и возраст, или раса и эмоция. Для этого в конце делают несколько «голов» (output heads) — например, разные Dense-слои для каждой задачи.
Такой подход может быть эффективнее, чем обучать несколько отдельных моделей, особенно если задачи между собой связаны по сути (анализ одних и тех же фич лица).
5. Пример кода (Keras): классификация эмоций
Ниже приведён упрощённый пример. Можно адаптировать его под любую категорию (пол, тип внешности и т.д.).
import tensorflow as tf
from tensorflow.keras import layers, models
import numpy as np
# Допустим, у нас уже есть набор лиц X_train, X_val
# (krop лиц 48×48 или 64×64, например), и метки эмоций y_train, y_val:
# X_train.shape -> (N, 64, 64, 3)
# y_train.shape -> (N,)
# где N — число образцов, а y — индексы классов эмоций
num_emotions = 7 # К примеру, 7 основных эмоций
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation=’relu’, input_shape=(64, 64, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation=’relu’),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(128, (3, 3), activation=’relu’),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(128, activation=’relu’),
layers.Dropout(0.3),
layers.Dense(num_emotions, activation=’softmax’)
])
model.compile(optimizer=’adam’,
loss=’sparse_categorical_crossentropy’,
metrics=[‘accuracy’])
model.summary()
# Обучение
EPOCHS = 10
BATCH_SIZE = 32
history = model.fit(
X_train, y_train,
epochs=EPOCHS,
validation_data=(X_val, y_val),
batch_size=BATCH_SIZE
)
Предсказание
# Пример классификации одной картинки (кропа лица)
face_img = X_val[0] # возьмём 1-й пример из валидации
face_img = np.expand_dims(face_img, axis=0) # (1, 64, 64, 3)
pred = model.predict(face_img)
class_id = np.argmax(pred, axis=1)[0]
confidence = pred[0][class_id]
print(f»Определена эмоция: {class_id}, уверенность: {confidence:.2f}»)
Примечание: Для пола или расы вместо num_emotions указывается соответствующее количество категорий (2 для бинарной классификации пола, больше для расовых/этнических групп и т.д.). Если хочется многозадачность, можно в конце делать несколько выходных слоёв (по одному на каждую задачу) и использовать Keras Functional API или Model для более гибкой компоновки.
Для предсказания возраста стоит делать на выходе линейный слой, предсказывающий непрерывное значение.
6. Особенности и сложности
1. Дисбаланс классов
При классификации расы или определённых типов внешности критически важно, чтобы в датасете были равномерно представлены все категории. Иначе модель может сильнее «натренироваться» на преобладающем классе.
2. Этические аспекты
Классификация людей по расе, типу внешности, полу и другим признакам нередко вызывает вопросы о конфиденциальности, приватности и дискриминации. Перед применением таких систем важно учитывать законы и этические нормы.
Могут возникать предвзятости модели (bias), если данные собраны неравномерно (например, преобладание молодых лиц одной этнической группы в обучающей выборке).
3. Эмоциональные состояния
Эмоции — это континуум, а не строго разграниченные категории, поэтому даже человеку бывает сложно определить, какую эмоцию на самом деле выражает лицо.
Освещение, качество изображения, мимика и культура влияют на результат.
4. Условная точность
Модель может хорошо работать в контролируемых условиях (студийные фото, фронтальная камера), но терять качество в реальной среде с шумом, различными ракурсами и освещением.
5. Дополнительные фичи
Иногда к лицу добавляют контекст (одежда, окружение) или речь (видео с голосом) — это может улучшать точность в задачах определения пола или эмоций в видео.
7. Выводы
● Классификация лиц на пол, расу, эмоции, возраст — это стандартная задача на CNN, аналогичная общей классификации.
● Ключевая разница в том, что предварительно нужно вырезать лицо (детектировать) и желательно выровнять его (face alignment).
● Обучение проводится на специализированных датасетах, где каждая категория (пол, эмоция и т.д.) размечена.
● Стоит учитывать дисбаланс классов, использовать аугментацию и быть внимательным к этическим вопросам.
В итоге, методы глубинного обучения позволяют строить достаточно точные системы классификации лиц по различным признакам, но для реального применения необходимы тщательно подобранные данные и ответственное отношение к вопросам приватности и возможных социальных последствий.